This function performs single-cell reference mapping using the K-nearest neighbor (KNN) method. It takes two single-cell datasets as input: srt_query and srt_ref. The function maps cells from the srt_query dataset to the srt_ref dataset based on their similarity or distance.
Usage
RunKNNMap(
srt_query,
srt_ref,
query_assay = NULL,
ref_assay = NULL,
ref_umap = NULL,
ref_group = NULL,
features = NULL,
nfeatures = 2000,
query_reduction = NULL,
ref_reduction = NULL,
query_dims = 1:30,
ref_dims = 1:30,
projection_method = c("model", "knn"),
nn_method = NULL,
k = 30,
distance_metric = "cosine",
vote_fun = "mean"
)Arguments
- srt_query
An object of class Seurat storing the query cells.
- srt_ref
An object of class Seurat storing the reference cells.
- query_assay
A character string specifying the assay name for the query cells. If not provided, the default assay for the query object will be used.
- ref_assay
A character string specifying the assay name for the reference cells. If not provided, the default assay for the reference object will be used.
- ref_umap
A character string specifying the name of the UMAP reduction in the reference object. If not provided, the first UMAP reduction found in the reference object will be used.
- ref_group
A character string specifying a metadata column name in the reference object to use for grouping.
- features
A character vector specifying the features to be used for calculating the distance metric. If not provided, the function will use the variable features calculated by the Seurat package.
- nfeatures
A integer specifying the number of highly variable features to be calculated if
featuresis not provided.- query_reduction
A character string specifying the name of a dimensionality reduction in the query object to use for calculating the distance metric.
- ref_reduction
A character string specifying the name of a dimensionality reduction in the reference object to use for calculating the distance metric.
- query_dims
A numeric vector specifying the dimension indices from the query reduction to be used for calculating the distance metric.
- ref_dims
A numeric vector specifying the dimension indices from the reference reduction to be used for calculating the distance metric.
- projection_method
A character string specifying the projection method to use. Options are "model" and "knn". If "model" is selected, the function will try to use a pre-trained UMAP model in the reference object for projection. If "knn" is selected, the function will directly find the nearest neighbors using the distance metric.
- nn_method
A character string specifying the nearest neighbor search method to use. Options are "raw", "annoy", and "rann". If "raw" is selected, the function will use the brute-force method to find the nearest neighbors. If "annoy" is selected, the function will use the Annoy library for approximate nearest neighbor search. If "rann" is selected, the function will use the RANN library for approximate nearest neighbor search. If not provided, the function will choose the search method based on the size of the query and reference datasets.
- k
An integer specifying the number of nearest neighbors to find for each cell in the query object.
- distance_metric
A character string specifying the distance metric to use for calculating the pairwise distances between cells. Options include: "pearson", "spearman", "cosine", "correlation", "jaccard", "ejaccard", "dice", "edice", "hamman", "simple matching", and "faith". Additional distance metrics can also be used, such as "euclidean", "manhattan", "hamming", etc.
- vote_fun
A character string specifying the function to be used for aggregating the nearest neighbors in the reference object. Options are "mean", "median", "sum", "min", "max", "sd", "var", etc. If not provided, the default is "mean".
Examples
data("panc8_sub")
srt_ref <- panc8_sub[, panc8_sub$tech != "fluidigmc1"]
srt_query <- panc8_sub[, panc8_sub$tech == "fluidigmc1"]
srt_ref <- Integration_SCP(srt_ref, batch = "tech", integration_method = "Seurat")
#> [2023-11-21 07:42:53.812178] Start Seurat_integrate
#> [2023-11-21 07:42:53.816329] Spliting srtMerge into srtList by column tech... ...
#> [2023-11-21 07:42:53.954418] Checking srtList... ...
#> Data 1/4 of the srtList is raw_normalized_counts. Perform NormalizeData(LogNormalize) on the data ...
#> Perform FindVariableFeatures on the data 1/4 of the srtList...
#> Data 2/4 of the srtList is raw_normalized_counts. Perform NormalizeData(LogNormalize) on the data ...
#> Perform FindVariableFeatures on the data 2/4 of the srtList...
#> Data 3/4 of the srtList is raw_counts. Perform NormalizeData(LogNormalize) on the data ...
#> Perform FindVariableFeatures on the data 3/4 of the srtList...
#> Data 4/4 of the srtList is raw_counts. Perform NormalizeData(LogNormalize) on the data ...
#> Perform FindVariableFeatures on the data 4/4 of the srtList...
#> Use the separate HVF from srtList...
#> Number of available HVF: 2000
#> [2023-11-21 07:42:55.721681] Finished checking.
#> [2023-11-21 07:42:56.252578] Perform FindIntegrationAnchors on the data...
#> [2023-11-21 07:43:07.212307] Perform integration(Seurat) on the data...
#> [2023-11-21 07:43:12.228872] Perform ScaleData on the data...
#> [2023-11-21 07:43:12.374605] Perform linear dimension reduction (pca) on the data...
#> Warning: The following arguments are not used: force.recalc
#> Warning: The following arguments are not used: force.recalc
#> [2023-11-21 07:43:13.102791] Perform FindClusters (louvain) on the data...
#> [2023-11-21 07:43:13.207305] Reorder clusters...
#> [2023-11-21 07:43:13.271599] Perform nonlinear dimension reduction (umap) on the data...
#> Non-linear dimensionality reduction(umap) using Reduction(Seuratpca, dims:1-11) as input
#> Found more than one class "dist" in cache; using the first, from namespace 'BiocGenerics'
#> Also defined by ‘spam’
#> Found more than one class "dist" in cache; using the first, from namespace 'BiocGenerics'
#> Also defined by ‘spam’
#> Non-linear dimensionality reduction(umap) using Reduction(Seuratpca, dims:1-11) as input
#> Found more than one class "dist" in cache; using the first, from namespace 'BiocGenerics'
#> Also defined by ‘spam’
#> Found more than one class "dist" in cache; using the first, from namespace 'BiocGenerics'
#> Also defined by ‘spam’
#> [2023-11-21 07:43:22.01769] Seurat_integrate done
#> Elapsed time: 28.21 secs
CellDimPlot(srt_ref, group.by = c("celltype", "tech"))
 # Projection
srt_query <- RunKNNMap(srt_query = srt_query, srt_ref = srt_ref, ref_umap = "SeuratUMAP2D")
#> Use the features to calculate distance metric.
#> Detected srt_query data type: raw_normalized_counts
#> Detected srt_ref data type: log_normalized_counts
#> Warning: Data type is unknown or different between srt_query and srt_ref.
#> Use 648 features to calculate distance.
#> Use 'raw' method to find neighbors.
#> Running UMAP projection
#> 07:43:22 Read 200 rows
#> 07:43:22 Processing block 1 of 1
#> 07:43:22 Commencing smooth kNN distance calibration using 2 threads
#> with target n_neighbors = 30
#> 07:43:22 Initializing by weighted average of neighbor coordinates using 2 threads
#> 07:43:22 Commencing optimization for 200 epochs, with 6000 positive edges
#> 07:43:23 Finished
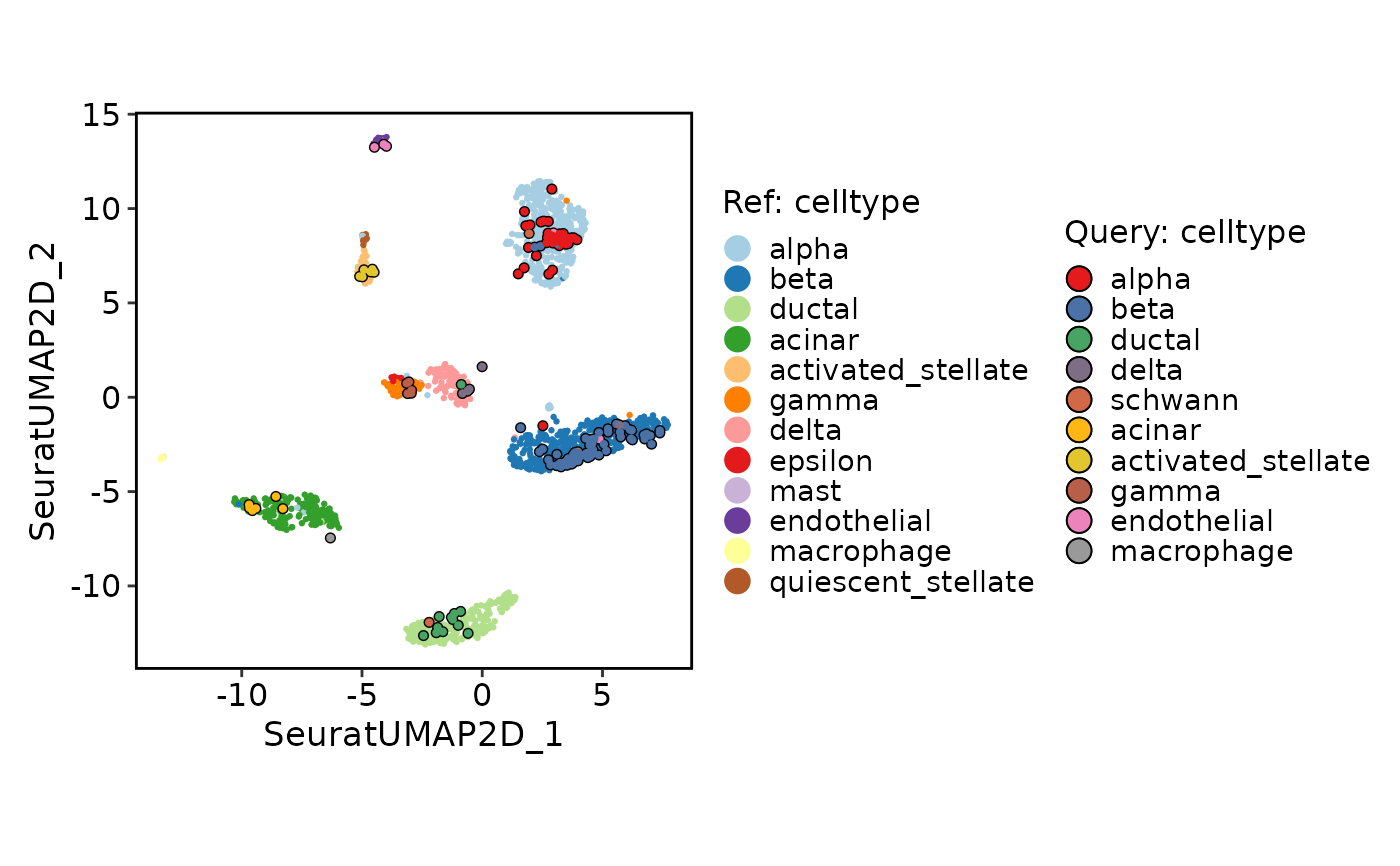
ProjectionPlot(srt_query = srt_query, srt_ref = srt_ref, query_group = "celltype", ref_group = "celltype")
#> Scale for x is already present.
#> Adding another scale for x, which will replace the existing scale.
#> Scale for y is already present.
#> Adding another scale for y, which will replace the existing scale.
# Projection
srt_query <- RunKNNMap(srt_query = srt_query, srt_ref = srt_ref, ref_umap = "SeuratUMAP2D")
#> Use the features to calculate distance metric.
#> Detected srt_query data type: raw_normalized_counts
#> Detected srt_ref data type: log_normalized_counts
#> Warning: Data type is unknown or different between srt_query and srt_ref.
#> Use 648 features to calculate distance.
#> Use 'raw' method to find neighbors.
#> Running UMAP projection
#> 07:43:22 Read 200 rows
#> 07:43:22 Processing block 1 of 1
#> 07:43:22 Commencing smooth kNN distance calibration using 2 threads
#> with target n_neighbors = 30
#> 07:43:22 Initializing by weighted average of neighbor coordinates using 2 threads
#> 07:43:22 Commencing optimization for 200 epochs, with 6000 positive edges
#> 07:43:23 Finished
ProjectionPlot(srt_query = srt_query, srt_ref = srt_ref, query_group = "celltype", ref_group = "celltype")
#> Scale for x is already present.
#> Adding another scale for x, which will replace the existing scale.
#> Scale for y is already present.
#> Adding another scale for y, which will replace the existing scale.